Steamで発売されているDICEOMANCERというStSフォロワーのゲームが中々に面白い。
が、残念なことにこのゲーム、日本語に対応していない。
最初は英語を読みながら頑張っていたが、ゲームの特性上かなり気合を入れて読む必要があり、流石に辛くなってきたので日本語化を試みることにした。
翻訳データをどうするか
最初はChatGPTで翻訳でもしようかと思っていたが、公式discordを見てみるとどうやらCrowdinには既に日本語の翻訳データは存在しているらしい。(あるなら反映してくれてもいいじゃんね...)
https://crowdin.com/project/diceomancer/ja
となれば後は言語ファイルを置き換えるだけなので問題は無さそうだ。
Export In XLIFFから一つのファイルでダウンロードすることが出来る。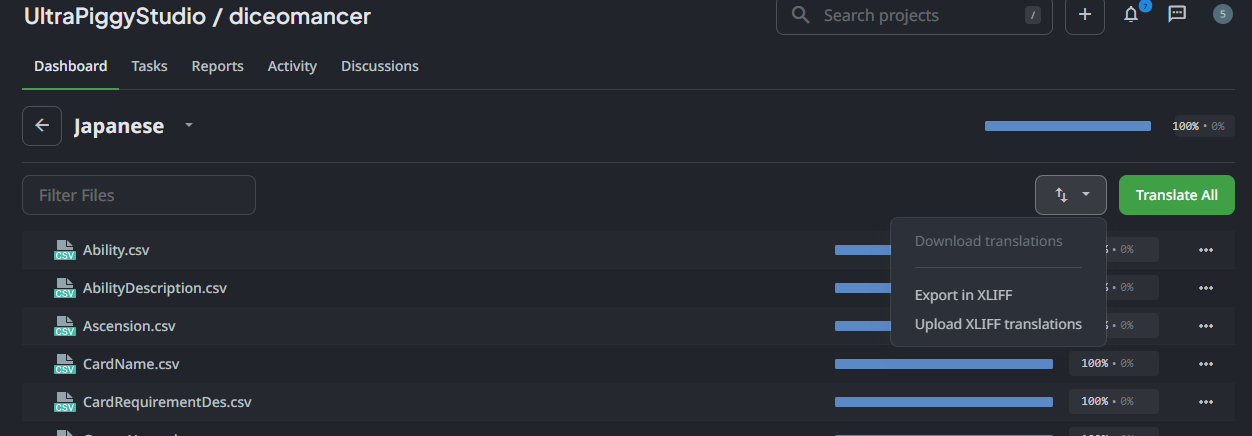
翻訳のアセットを探す
SteamLibrary\steamapps\common\DICEOMANCER\Diceomancer_Data\StreamingAssets\aa\StandaloneWindows64 あたりを覗いていると、翻訳ファイルっぽいものが見つかる。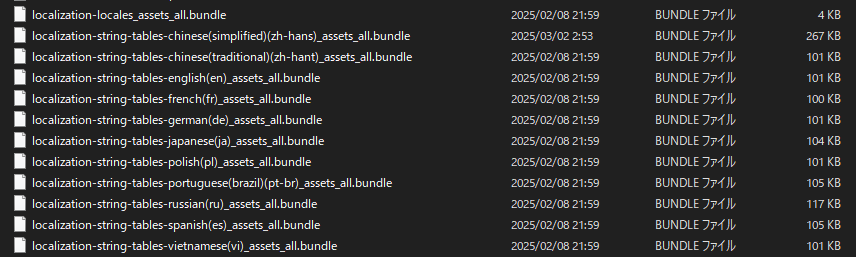
調べてみると、UnityのAssetBundleというものらしく、どうやらUABEというツールで抽出可能らしい。
これを使って、試しに中国語のファイルをdumpしてみるとこんな感じ。
0 MonoBehaviour Base
0 PPtr<GameObject> m_GameObject
0 int m_FileID = 0
0 SInt64 m_PathID = 0
1 UInt8 m_Enabled = 1
0 PPtr<MonoScript> m_Script
0 int m_FileID = 0
0 SInt64 m_PathID = -2378050947708348859
1 string m_Name = "Ability_zh-Hans"
0 LocaleIdentifier m_LocaleId
1 string m_Code = "zh-Hans"
0 PPtr<$SharedTableData> m_SharedData
0 int m_FileID = 1
0 SInt64 m_PathID = -6453478249562131148
0 MetadataCollection m_Metadata
0 IMetadata m_Items
0 Array Array (0 items)
0 int size = 0
0 TableEntryData m_TableData
0 Array Array (159 items)
0 int size = 159
[0]
0 TableEntryData data
0 SInt64 m_Id = 4318285824
1 string m_Localized = "燃烧"
0 MetadataCollection m_Metadata
0 IMetadata m_Items
0 Array Array (0 items)
0 int size = 0
これを置き換えていけば行けそうだ。
ハッシュチェック
で、適当に一個置き換えてみたが、
だめやんけ
ツールややり方がおかしいのかと思って、他のツールを試したりバイナリを比較したりしてみたがどうもだめなので、これは何か整合性のチェックをしているなという感じ。
っていうか、ファイル名を見るとなんか末尾ハッシュっぽい。Ability_zh-Hans-CAB-94da1c08ce5122fffd4ef4f65ff0dbbb-1042738465642658668.txt
ググるとやっぱりハッシュチェックをしているらしい。が、catalog.jsonの設定を変えればチェックを無効にできるっぽい。
HashチェックのあるAssets\.Bundleの改造の仕方|Bliz
できました。
やるだけ
というわけであとはdiceomancer_ja.xliff を基にlocalization-string-tables-chinese(simplified)(zh-hans)_assets_all.bundle
から抽出したこいつらの中身を置換していけばよい。
置換コード
import os
import re
import sys
import xml.etree.ElementTree as ET
def build_localization_map(xliff_path):
print(f"[INFO] Loading XLIFF file: {xliff_path}")
ns = {'x': 'urn:oasis:names:tc:xliff:document:1.2'}
localization_map = {}
try:
tree = ET.parse(xliff_path)
except Exception as e:
print(f"[ERROR] Failed to parse XLIFF file: {e}")
return localization_map
root = tree.getroot()
trans_units = root.findall('.//x:trans-unit', ns)
print(
f"[INFO] Found {len(trans_units)} trans-unit elements in the XLIFF file.")
for trans_unit in trans_units:
resname = trans_unit.get("resname")
if resname is None:
print("[WARN] Skipping a trans-unit without resname attribute.")
continue
try:
key = int(resname)
except ValueError:
print(f"[WARN] Invalid resname value (not an integer): {resname}")
continue
target_elem = trans_unit.find('x:target', ns)
value = ""
if target_elem is not None and target_elem.text is not None:
value = target_elem.text
# XLIFF内の改行はすべて文字列 "\n" に置換して1行にする
value = value.replace('\r\n', '\\n').replace(
'\r', '\\n').replace('\n', '\\n')
if value == "":
value = "<EMPTY>"
localization_map[key] = value
print(f"[DEBUG] Mapping: {key} -> {value}")
return localization_map
def update_txt_file(txt_input_path, localization_map):
print(f"[INFO] Processing txt file: {txt_input_path}")
try:
with open(txt_input_path, "r", encoding="utf-8") as f:
content = f.read()
except Exception as e:
print(f"[ERROR] Failed to read {txt_input_path}: {e}")
return None
# txtファイルは必ず1行である前提
# パターンは、m_Id ~ m_Localized のブロック全体をキャプチャする。
# ・group(1): m_Localized の前半部分(m_Id~m_Localized = ")
# ・group(2): m_Idの値(数字)
# ・group(3): m_Localized の値(非貪欲、次の "(直後に空白+数字または行末がある)まで)
# lookahead (?:"(?=\s+\d|$)) により、閉じの " はマッチ対象外とする
pattern = re.compile(
r'(m_Id\s*=\s*([-]?\d+).*?m_Localized\s*=\s*")(.*?)("(?=\s+\d|$))',
re.DOTALL
)
def replacer(match):
id_str = match.group(2)
try:
id_val = int(id_str)
except ValueError:
print(f"[WARN] Invalid m_Id value found: {id_str}")
return match.group(0)
old_val = match.group(3)
if id_val in localization_map:
new_val = localization_map[id_val]
print(f"[DEBUG] Replacing m_Localized for m_Id {id_val}:")
print(f" OLD: {old_val}")
print(f" NEW: {new_val}")
return match.group(1) + new_val + '"'
else:
print(
f"[DEBUG] m_Id {id_val} not found in localization map. No replacement.")
return match.group(0)
new_content = pattern.sub(replacer, content)
return new_content
def main(xliff_path, txt_input_dir, txt_output_dir):
print(f"[INFO] Starting processing with XLIFF file: {xliff_path}")
if not os.path.exists(txt_output_dir):
try:
os.makedirs(txt_output_dir)
print(f"[INFO] Created output directory: {txt_output_dir}")
except Exception as e:
print(f"[ERROR] Could not create output directory: {e}")
return
localization_map = build_localization_map(xliff_path)
if not localization_map:
print("[ERROR] Localization map is empty. Exiting.")
return
txt_files = [f for f in os.listdir(
txt_input_dir) if f.lower().endswith(".txt")]
if not txt_files:
print("[ERROR] No txt files found in the input directory.")
return
print(f"[INFO] Found {len(txt_files)} txt files to process.")
for filename in txt_files:
txt_input_path = os.path.join(txt_input_dir, filename)
new_content = update_txt_file(txt_input_path, localization_map)
if new_content is None:
print(f"[ERROR] Skipping file due to error: {filename}")
continue
txt_output_path = os.path.join(txt_output_dir, filename)
try:
with open(txt_output_path, "w", encoding="utf-8") as f:
f.write(new_content)
print(f"[INFO] Updated file written: {txt_output_path}")
except Exception as e:
print(
f"[ERROR] Failed to write output file {txt_output_path}: {e}")
if __name__ == "__main__":
if len(sys.argv) != 4:
print("Usage: python script.py <XLIFFファイルパス> <txt入力ディレクトリ> <txt出力ディレクトリ>")
sys.exit(1)
xliff_path = sys.argv[1]
txt_input_dir = sys.argv[2]
txt_output_dir = sys.argv[3]
main(xliff_path, txt_input_dir, txt_output_dir)
置換出来たら、UABEAのImport Dumpして保存すれば、置換済みのlocalization-string-tables-chinese(simplified)(zh-hans)_assets_all.bundleが出来上がるのでこれを元の位置に置いてあげればよい。
というわけで無事日本語化に成功したのでありました。
めでたしめでたし。